Less Detail, Better Answers:
Degradation-Driven Prompting for VQA
CVPRW 2026 Oral
Abstract
Recent advancements in Vision-Language Models (VLMs) have significantly pushed the boundaries of Visual Question Answering (VQA). However, high-resolution details can sometimes become noise that leads to hallucinations or reasoning errors.
In this paper, we propose Degradation-Driven Prompting (DDP), a novel framework that improves VQA performance by strategically reducing image fidelity to force models to focus on essential structural information. We evaluate DDP across two distinct tasks: Physical attributes and Perceptual phenomena. Our experimental results demonstrate that "less is more" by intentionally degrading visual inputs and providing targeted structural prompts. DDP enables VLMs to bypass distracting textures and achieve superior reasoning accuracy on challenging visual benchmarks.
Methodology: The DDP Framework
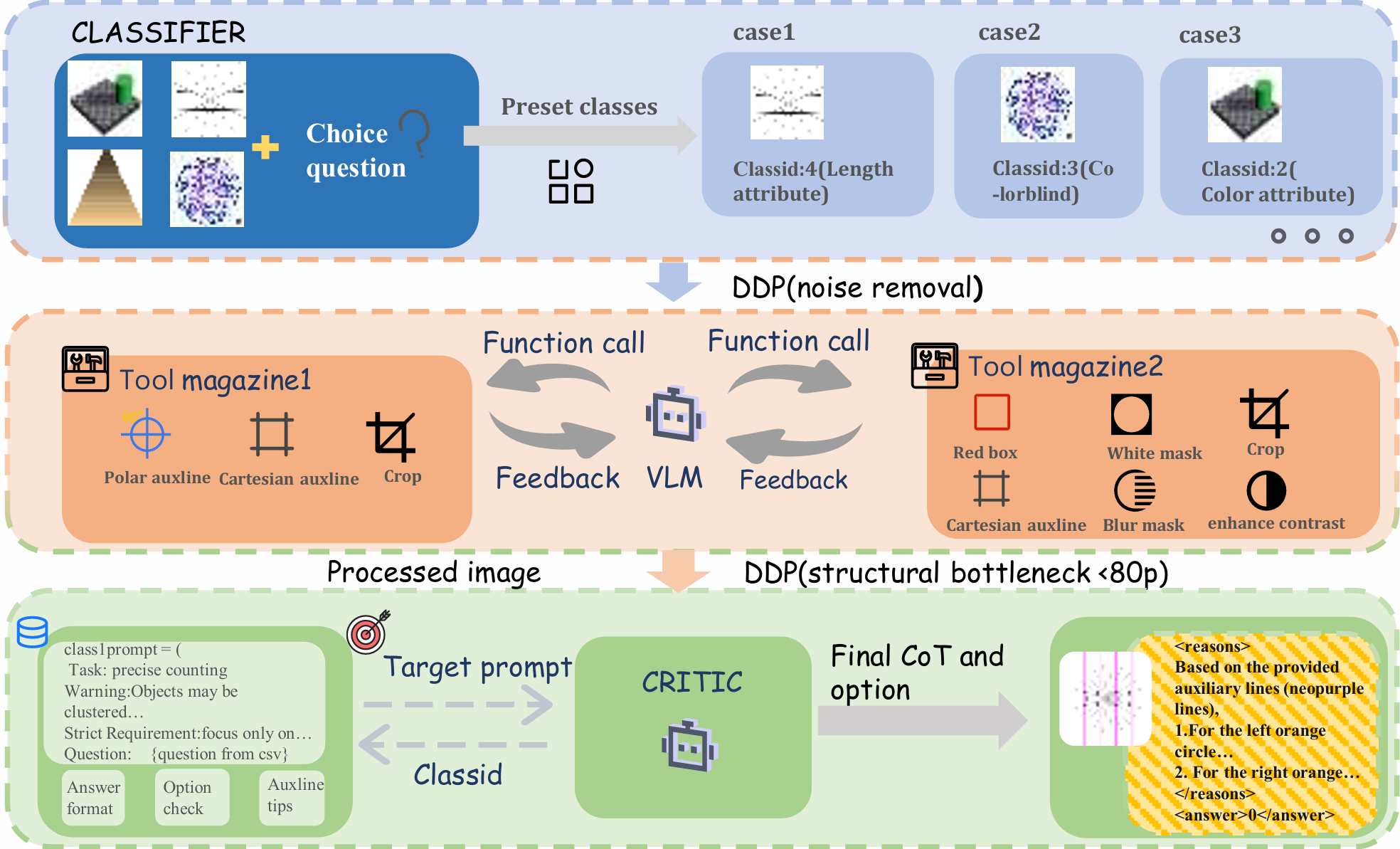 - DDP-based VLM enhancement framework (Classifier, Tool Manager, and Critic as three major stages)
- DDP-based VLM enhancement framework (Classifier, Tool Manager, and Critic as three major stages)
Our multi-stage reasoning pipeline is designed to reduce visual illusions in VLMs and includes the following three core stages:
1 Task Classification
A lightweight Gaussian smoothing is first applied to the input image to generate a coarse perceptual prior. The classifier then performs a two-level analysis and routes the task to either "Physical Attributes" (e.g., size, color) or "Perceptual Phenomena" (e.g., counting, spot-the-difference, motion illusion).
2 Tool Manager
First-level DDP downsampling is applied (compressed to about 150 pixels) to filter high-frequency noise. As an autonomous agent, the tool manager invokes predefined visual tools (e.g., crop, red box, polar/cartesian guide lines, blur masks) to decouple deceptive visual cues.
3 Target Prompting and Final Reasoning
The most aggressive DDP setting is applied by downsampling the image to below 80 pixels, forming a "structural bottleneck". This forces the critic model to discard misleading local textures and rely on global topology plus alignment prompts to produce structured chain-of-thought reasoning.
Experimental Results
1. DataCV CVPR Challenge (Track 1)
We are the 1st solution in this track. DDP demonstrates a substantial performance leap over standard models.
| Method | Original Images | Perturbed Images |
|---|---|---|
| Gemini-3-Pro | 89.52% | 66.19% |
| DDP (w/ Gemini-3-Pro) | 95.71% (+6.19%) | 86.19% (+20.00%) |
2. V*Bench (High-Resolution Visual Grounding)
Our model achieves a significant performance leap over standard multimodal large language models.
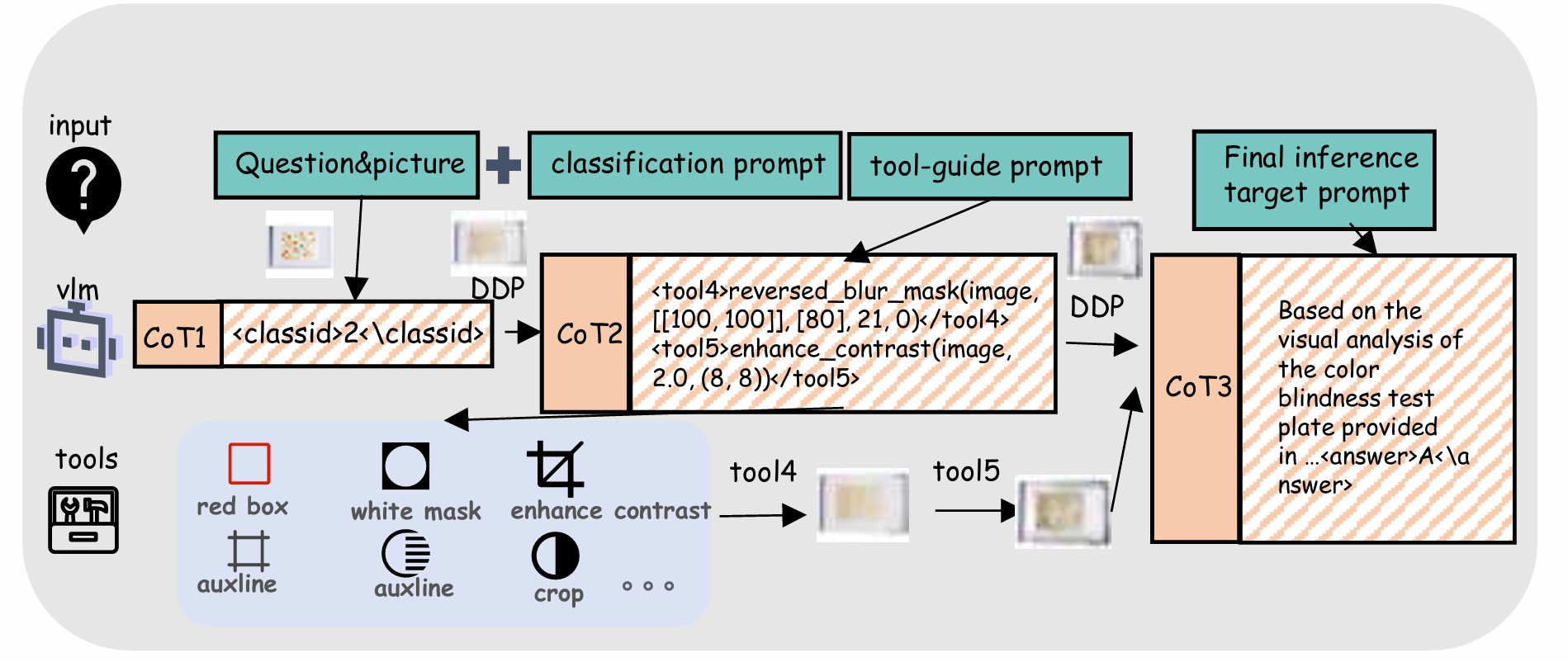 Case studies on V*Bench demonstrating improved grounding accuracy
Case studies on V*Bench demonstrating improved grounding accuracy
| Model | Attribute (%) | Spatial (%) | Overall (%) |
|---|---|---|---|
| GPT-4V | 51.3 | 60.5 | 55.0 |
| LLaVA-1.5-7B | 43.5 | 56.6 | 48.7 |
| Ours (DDP) | 89.2 | 89.5 | 89.3 |
3. TeT ColorBlind Dataset
On the extreme challenge of distinguishing subtle color variations, existing SOTA models (OpenAI o1, Claude-3-Sonnet, Gemini-2.5-Pro) fail to achieve a non-zero score.
Citation
If you find this project useful, please cite it as:
@article{han2026detailbetteranswersdegradationdriven,
title={Less Detail, Better Answers: Degradation-Driven Prompting for VQA},
author={Haoxuan Han and Weijie Wang and Zeyu Zhang and Yefei He and Bohan Zhuang},
journal={arXiv preprint arXiv:2604.04838},
year={2026}
}